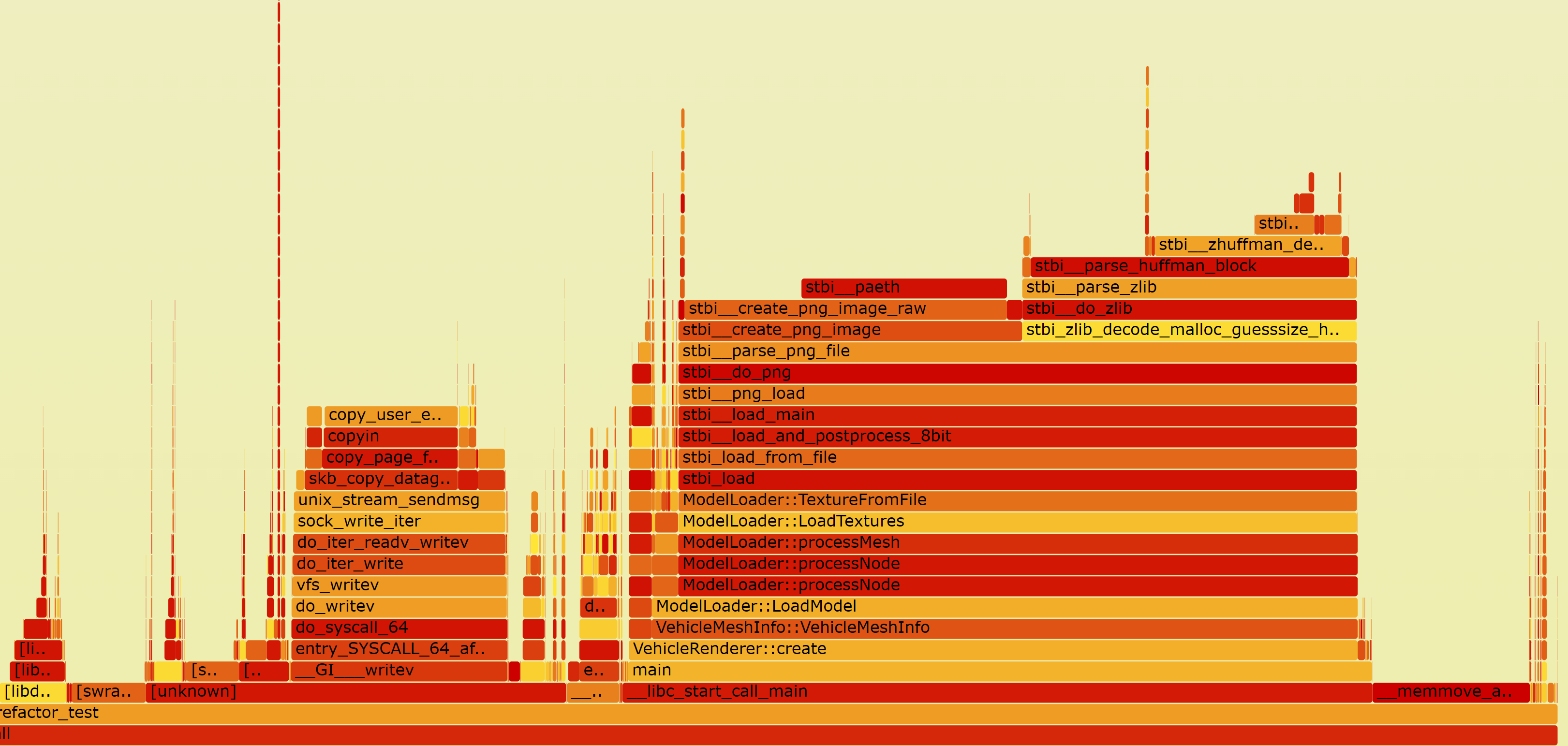
使用perf等工具看一下火焰图,检查一下时间都去哪了👀
减少uniform更新次数
使用UBO将多个uniform打包,并绑定到相应的mesh上,比如材质属性和纹理加载状态
TODO:会增加GPU内存开销,没具体验证过实际影响,也不一定是最佳实践 🤷♂️
layout (std140) uniform MaterialBlock { vec4 materialDiffuseColor; vec4 materialSpecularColor; float Opacity; float Shininess; float ShininessStrength; bool texture_diffuse_load; bool texture_specular_load; bool texture_normal_load; bool texture_ao_load; bool texture_alpha_load; bool texture_roughness_load; bool texture_metallic_load; bool texture_emissive_load; } material;
去重,能不更新就不更新
通过一定的逻辑和判断等等,减少不必要的uniform更新,比如在控制车门旋转的时候,这个车门的部件是可以共享一组uniform的,不需要为每个部件都更新一次设置。
png格式的纹理加载速度慢,使用其他GPU友好的格式
尝试了KTX格式,会比解码png快不少,大概几倍的样子,但上传到GPU的接口也是很耗时的,即使使用这种格式也需要多线程异步加载。在OpenGL中需要做上下文贡献。 TODO: 有时间的话研究一下 🤫
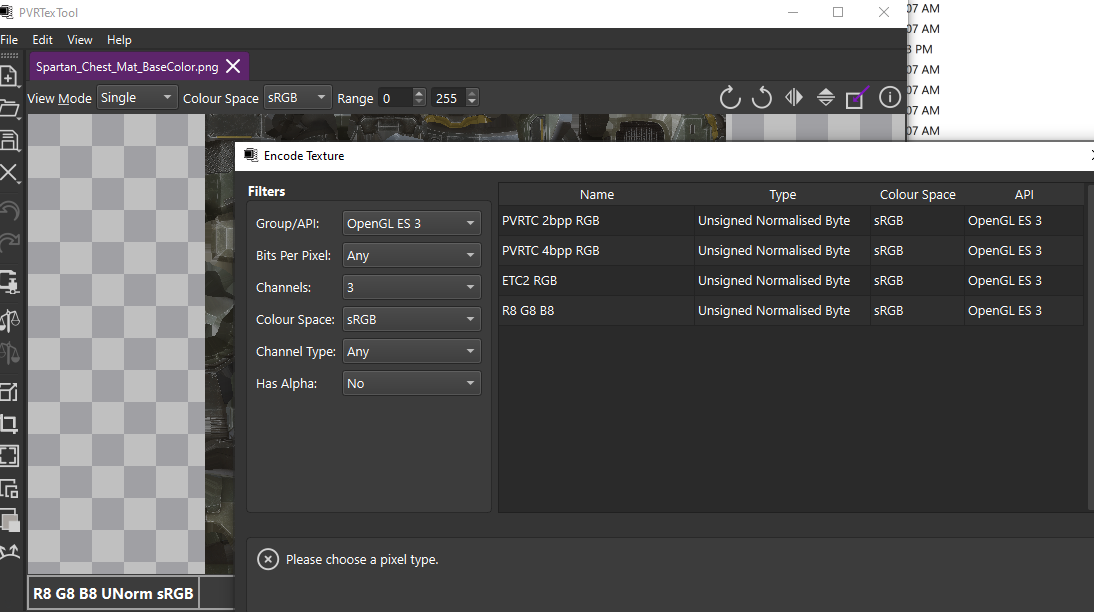
- 使用的工具 PVRTexToolGUI(官网下载的)
- 有个选项是 Encode Texture:
- 选择对应的配置就可以看到ETC2格式了
- KTX相关的库是在github上下载的,因为只在X86的ubuntu做了验证,实际项目中可能需要交叉编译
- 基本的加载步骤可以参考这个,AI生成的,但可以运行 ktx demo
多线程加载纹理资源
在初始化的时候使用多线程一次性将所有图像资源都加载到内存中,使用的时候直接查找。会比线型加载快很多。在模型加载解析完成之后统一释放资源。 可以参考这笔提交github about optimization
缺点
- 内存开销增加
- CPU loading 很高
- 上传到GPU仍然需要时间
待办
- 探索生成纹理及上传到GPU的这个过程是否也可以做异步
- 使用的是stbi软解方式,在特定的环境中可以有硬解接口
有些纹理资源存在不必要的多余通道,可以删掉
- 注意在着色器中区分纹理是单通道还是多通道, 对于ao,specular,Metallic, Roughness 这些贴图,一般是单通道的,如果把单通道纹理当做多通道纹理使用,显示出来的结果会偏红色
- 可以在linux上使用file命令查看:8-bit grayscale,8-bit colormap(?3通道), 8-bit/color RGB, 8-bit/color RGBA
- 可以使用GIMP将8-bit colormap转换为灰度图,
图像 → 模式 → 灰度 - 删除alpha通道的时候注意设置背景色,
layer → transparency → remove alpha channel